Getting Started with Azure Data Factory v2
Azure Data Factory (ADF)—a fully-managed service for composing data storage, processing and movement services in the form of data pipelines—orchestrates data movements and transformations with a zero-code approach.
In this blog, I’ll explain the differences between ADF version 1 (ADFv1) and ADF version 2 (ADFv2), then show you how to get started with ADFv2 so you can develop and manage data pipelines easily.
ADFv1 vs. ADFv2—What’s the Difference?
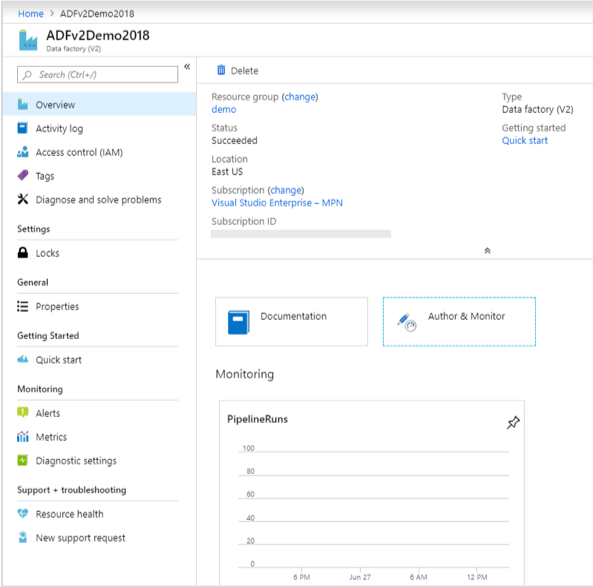
The initial iteration, ADFv1, had far fewer features and required more coding of JSON style documents than the current version—ADFv2. But now, ADFv2 features a very rich and intuitive user interface (UI) known as “visual tools,” which not only enables interactive visual authoring and monitoring of pipelines right from the web browser, but is also very similar to the SSIS development experience. What does this mean? It means no need to download and install software, add-ins or templates to start developing; you simply start developing right from the authoring and monitoring tile in your ADFv2 service blade as seen in Figure 1 below.
In addition to having a similar development style as SSIS, ADFv2 now supports execution of SSIS packages via a new Integration Runtime referred to as the Azure-SSIS Integration Runtime. ADFv2 has many other new features, too: The ability to separate orchestration logic and transformation logic into control flow and data flow workflows correspondingly; the ability to manage code via native GIT integration; and the ability to execute pipelines based on a schedule or triggered by an event. (Want a more in-depth comparison between ADFv1 and ADFv2? Refer to Microsoft’s comparison chart).
Provisioning a Data Factory
ADFv2 can be provisioned from the Azure portal user interface or programmatically through PowerShell, .NET, Python, REST API or ARM templates as described in this quickstart guide. Once provisioned, you can start developing pipelines directly from the Azure portal or programmatically using the previously mentioned programming languages.
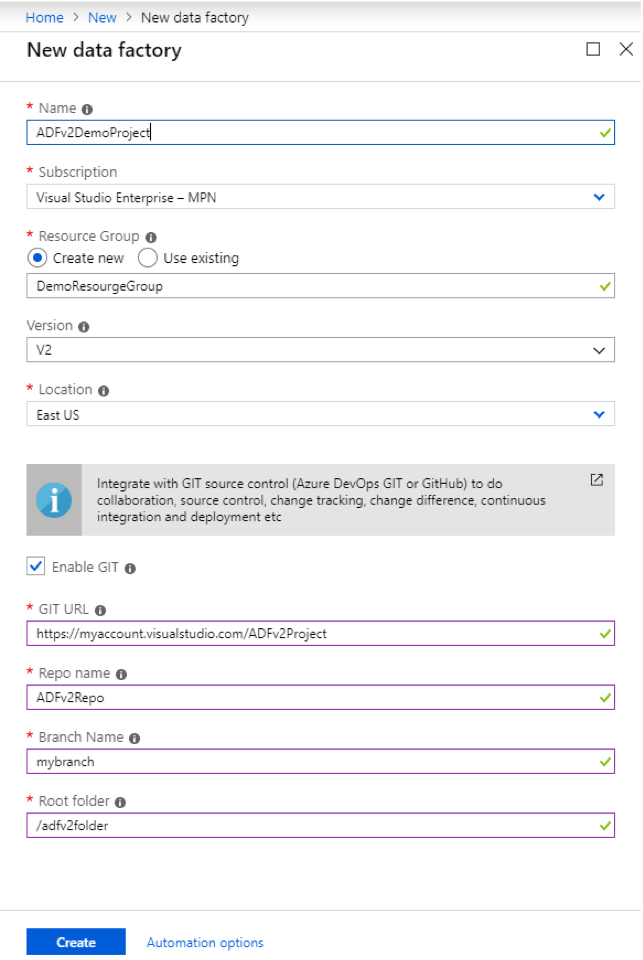
Below, Figure 2 shows the Azure portal UI dialog for provisioning a new data factory. It asks you to provide a globally unique name for your data factory, a subscription, resource group and the location of your data factory. By default, Version 2 is selected; you can also specify whether you want to integrate with GIT repository by enabling
the Enable GIT option.
Pipelines, Datasets and Activities
ADFv2 can have one or more pipelines—or logical groupings of activities that work simultaneously to perform a task, like copying and transforming data or executing a Spark job. Activities can be grouped as:
- Data movement activities
- Data transformation activities
- Control activities
An activity may have input and output datasets. These datasets may include data contained in a database; in files and folders; or other data sources including web APIs and other data feeds. Datasets provide data for inputs or outputs along with their corresponding metadata such as column names and data types. An input dataset provides the data that the activity will copy or apply transformations to. On the other hand, an output dataset represents the output of the activity; it is either the unchanged input data to be copied, or it’s the transformed data to be inserted to a different target store known as the sink.
To define a dataset, you must first create a linked service, which acts as the connecting string to the data source. For example, a linked service may be your connection to a SQL Server database for which you specify a SQL Server host, port number, database name, credentials and any other parameters required to connect to the data source.
After your linked service is defined, you can create a dataset by specifying a schema and any required parameters. The schema can be defined manually; may be imported from a schema file; or input dynamically from the source’s metadata or programmatically through dynamic content. (For more help, read Microsoft’s documentation on expressions and functions in Azure Data Factory).
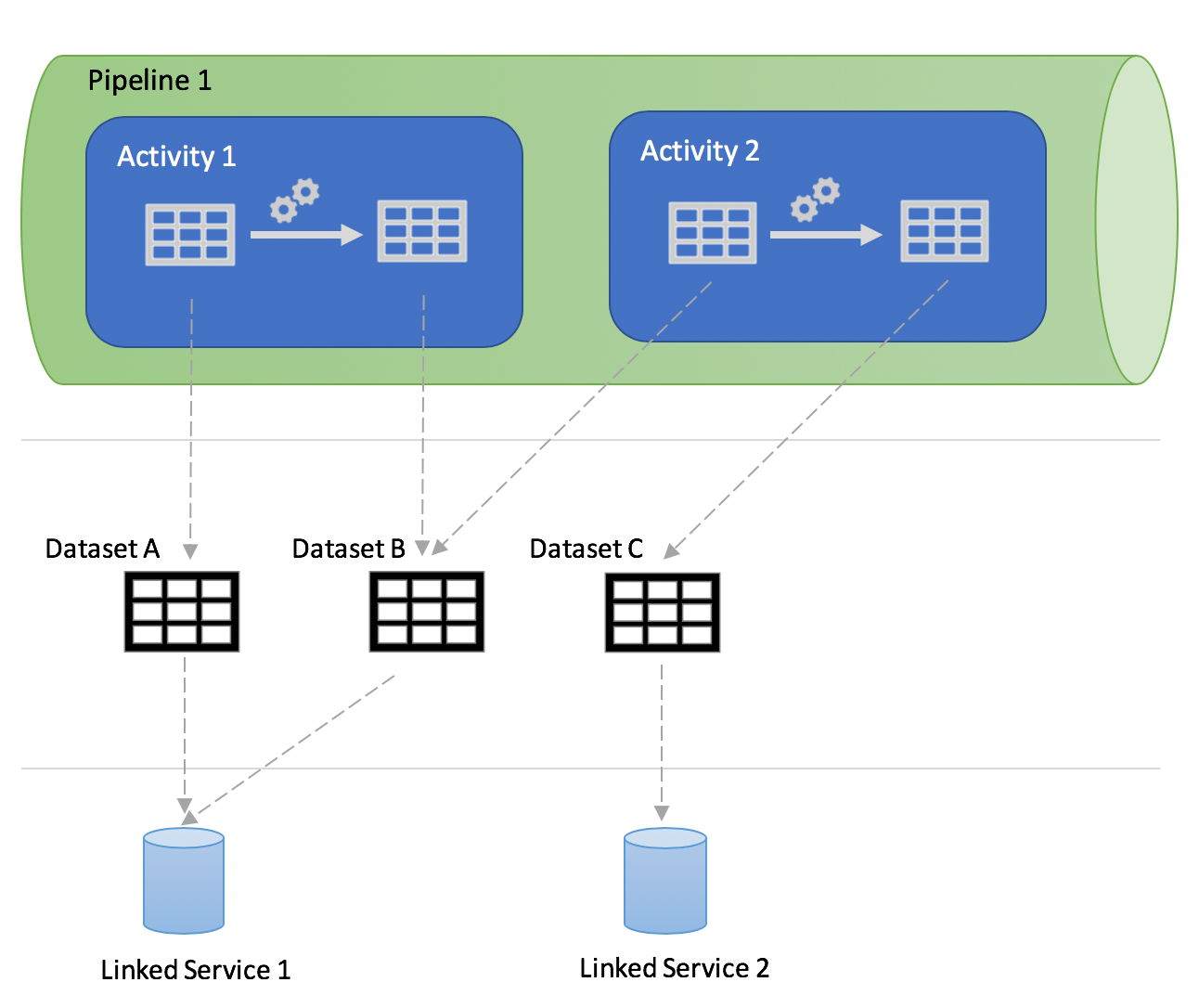
Furthermore, each of the items mentioned above have specific relationships (as illustrated in Figure 3 below): For example, a linked service can be referenced by one or more datasets. Meanwhile, a dataset can be referenced by one or more activities as either an input dataset or an output (sink) dataset. Additionally, a pipeline can contain one or more activities that run in parallel, based on an if-condition or based on the outcome of a previous activity. The available outcomes include: success, failure, completion or skipped.
Mapping Data Flows
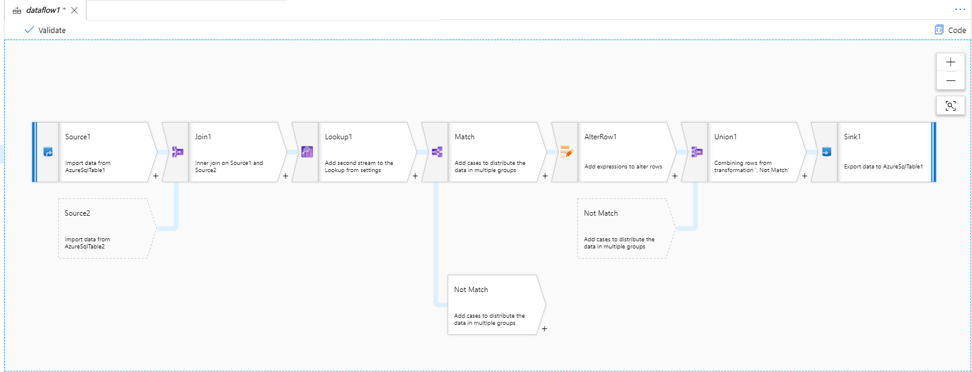
Data flow activity is a new, specialized activity that allows ETL/ELT developers to build data transformation logic with a rich graphical user interface without writing code. Figure 4 below shows an example of a mapping data flow.
Data flow activities require at least one source and one sink (destination). Data flow activities are currently powered by Azure Databricks clusters and include the following transformations:
Multiple Inputs/Outputs
Schema Modifier
Row Modifier
Destination
As of this writing, data flow is a new feature in public preview, so some features may be subject to change. For more information on each of these transformations, please refer to Microsoft’s Azure Data Factory documentation.
Developing a Pipeline to Copy Data
Copying data from a source to a destination is one of the most common activities in ADFv2. You can do this by developing a pipeline from scratch or by following the handy Copy Data Wizard shortcut right from the ADFv2 Overview.
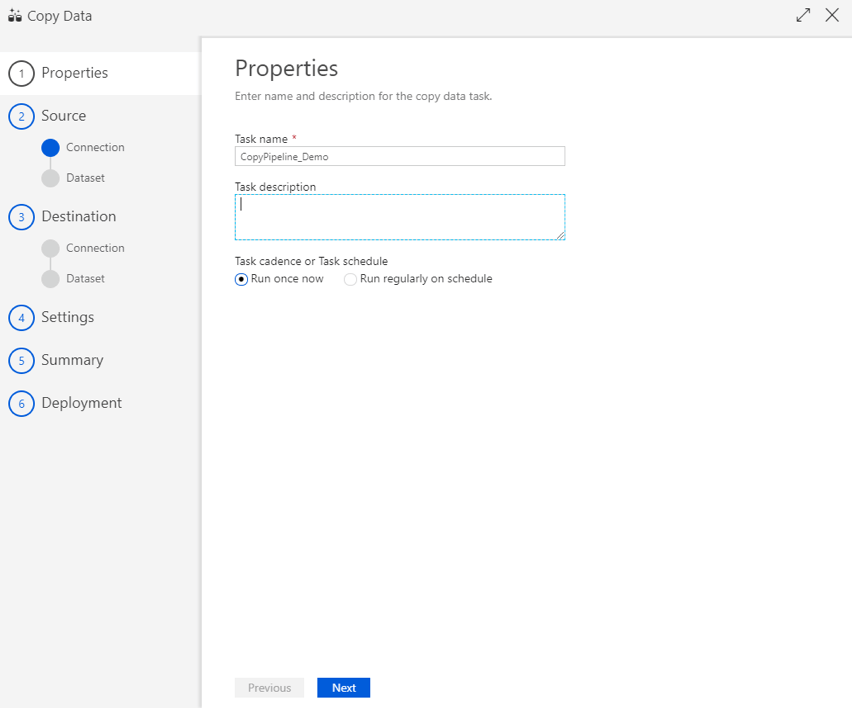
In the Copy Data Wizard, you must specify a source data store (also referred to as a linked service); a dataset based on a file, table, view or query; and the destination data store to map the output dataset. The Copy Data Wizard then creates a simple pipeline with a single activity that can be run manually or on a scheduled basis. Below, Figure shows the Copy Data Wizard dialog screen.
Executing an SSIS Package Activity in ADFv2
One of ADFv2’s most exciting new capabilities is its ability to deploy, execute and monitor SSIS Packages from an ADFv2 pipeline. This allows organizations to “lift and shift” their existing ETL/ELT workloads running on-prem to the cloud with little effort.
To deploy SSIS packages to ADFv2, you first need to provision an Azure-SSIS Integration Runtime once. You can either do this by using the shortcut labeled “Configure SSIS Integration” in the UI or by using PowerShell. (You can also read Microsoft’s helpful guide to learn how to provision the Azure-SSIS Integration Runtime).
Once provisioned, you can deploy the SSIS packages from Visual Studio, ISPAC deployment file and other tools such as SQL Server Data Tools (SSDT) and SQL Server Management Studio (SSMS). During the SSIS packages deployment process, you must specify the Azure SQL Database or managed instance server that the Azure-SSIS Integration Runtime is associated with. This database server will also host the SSIS Catalog (SSISDB).
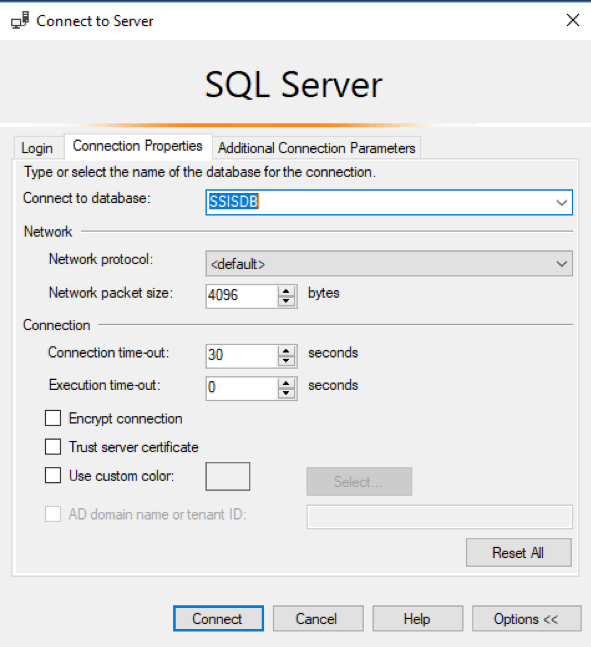
TIP: To connect to the SSIS Catalog with SSMS, go to the connection properties tab of the dialog box and specify “SSISDB” as the database to connect to (as shown in Figure 6 below).
That’s it—you’re now ready to use ADFv2. To learn more about the benefits of ADFv2 and how it can be used in conjunction with Azure Data Lake Gen 2, register for our webinar, “Loading Data into Azure Data Lake Gen 2 with Azure Data Factory v2.”