Classifying Cloud Data Science Tools: Which Ones Do You Really Need?
Classification systems work wonders for organizing large or complex collections. They came in handy when people first started studying life on earth and realized that they could bucket living things into a hierarchy for indexing—known as phyla—instead of combing through individual lists of species. Similarly, they can be used to help simplify the world of data science, where we are just beginning to scientifically study the tools that we use to build self-driving cars, go-grand champions and movie recommenders.
As neural networks demand more compute power, cloud providers are seizing every opportunity to provide this power by rolling out a wave of data science tools for training, tuning and deploying models. But, much, like early researchers found while studying life on earth, these individual lists of tools have quickly become overwhelming.
To help you navigate these lists of tools and figure out what is right for you, here’s our own list of “phyla” for data science tools:
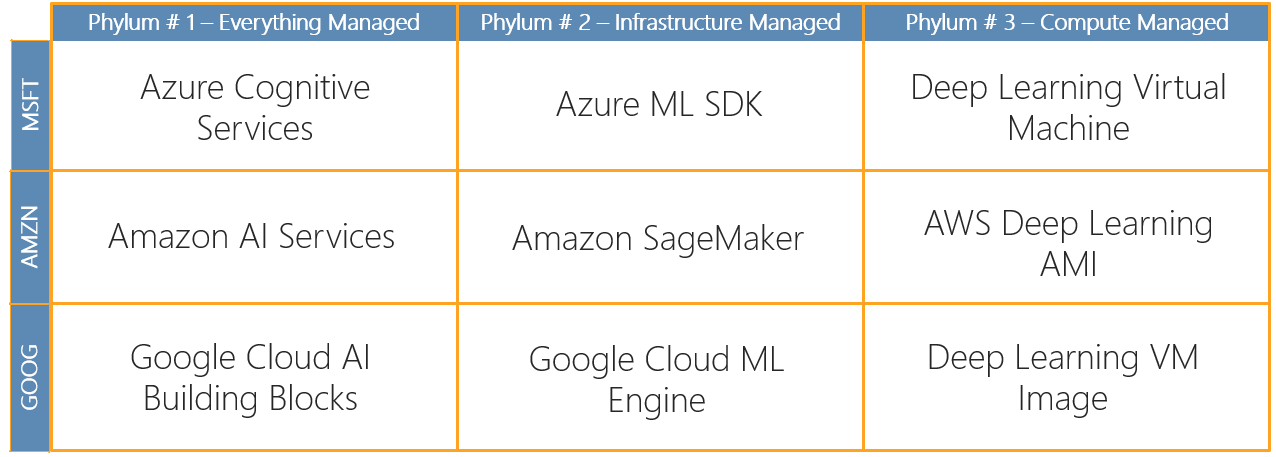
Phylum 1: Everything Managed
Tools in this phylum only require a simple API call, so you don’t have to manage training data, training models or even deploying models. For example, once you get your subscription key, you’ll make an API call by passing the key and the required inputs (an image for example), and the API returns predictions. Note: these typically charge on a per call basis.
Phylum 2: Infrastructure Managed
Tools in this phylum require you to manage training data, training models, and deploying models. In fact, you’re building custom AI here! However, there are utilities that will make this easier. For example, you could define the model you want to train and the data you’d like to use, then submit a job to cloud compute resources to train the model and drop the resulting model to a specific storage location like blob storage. For deployment, you would configure it and then submit it to a service, like Azure Kubernetes Service, to be deployed.
Phylum 3: Compute Managed
From writing your own utilities to provisioning hardware, tools in this phylum require you to do almost everything. For example, you’d spin up your own virtual machine (most cloud providers make preconfigured images available), define your model, train the model, evaluate it and save it with your own code. For deployment, you’d write your app server (most likely using Flask), package it with your model in a Docker container for your virtual machine(s) to grab, then spin up the virtual machine(s) and optionally define a load balancer.
Getting Started
So, you’re probably wondering, which phylum is right for me? The answer depends on your organization’s AI maturity and the complexity of the data science problem that you’re trying to solve. If you don’t have data or data scientists, you’d probably start with tools from phylum one. If you have some data and a relatively new data science team, you’d want to consider using tools from phylum 2. If you need complete control of your application—or want to be completely provider-agnostic—then you’ll need to select tools from phylum 3.
Essentially, you can think of the phyla as a spectrum going from complete control and lots of coding for your utilities to no control and no coding of utilities required. Keep in mind, though, when it comes to finding the right phylum, there’s no silver bullet. For example, if an organization with high AI maturity needs to solve a relatively simple data science problem, it would be more efficient for them to use tools from phylum 1. As cloud providers rapidly advance their data science tools, you’ll be able to solve more complex data science problems with tools that require less control and coding.
Want to know which cloud data science tools are best for your AI initiative(s), and how you can get started? Ask us about Predictive Analytics Discovery and learn how we can help.